餌も水も足りている。天敵もいない。それでも、ネズミの群れは壊れる。Calhoun の Universe 25* がそうだった。なぜ壊れるのかを、自分のコードで確かめたい。
ただ、崩壊をいきなり作ることはしない。崩壊をコードに書けば、観察ではなく、最初から決めた結末になる。だから、最小の装置、一匹からはじめる。
ひとつ断っておく。ここで作るネズミは、本物の再現ではない。ネズミの皮をかぶった最小の個体で、社会が崩れたり残ったりする条件を見るための思考実験。コードも、動く実装ではなく、考えを示す概念的な擬似コード。この前提はシリーズ全体に共通するので、以降はくり返さない。
一匹を、箱に入れる。餌の場所も、レバーの意味も知らない。できるのは、試すことだけ。歩いて、レバーを押して、結果を受け取る。その結果で、次の選び方だけが少し変わる。
action = choose_action(rat, world)
outcome = apply(world, action)
learn!(rat, outcome)
正解は教えない。この短い循環を、ただ回す。それが、あとで作るものすべての土台になる。しばらく走らせると、一匹は、腹が減るとレバーへ行き、押して、食べるようになった。一日の収支は、餓死寸前の赤字から黒字へ。

条件を一つ変える。空腹を体の内側の状態にして、レバーと餌の場所を引き離す。装置が一段複雑になる。また走らせて、観察する。
しばらくは、うまくいっていた。800日目で、性能が突然ゼロに落ちた。
探索のノイズを疑ったが違った。学習を止めて評価しても、同じ場所で落ちる。壊れたのは、行動の選び方そのものだった。
視点を、脳から入力へ移す。一匹は匂いの方向だけを見て、強さを見ていない。だから、近くの餌も遠くの餌も、方向が同じなら同じ入力になる。
何が起きるか。異なる場所が、同じ入力に潰れていた。その入力で選ばれる行動が変わると、同じ入力を持つ場所すべてで、行動が同時に変わる。突然、かつ全体に及んだのは、これが理由だ。
装置を一つだけ直す。入力に、匂いの強さを足す。本物のネズミも、源に近づくほど匂いを強く感じる。脳も、学習のしかたも、変えていない。崩落は消えた。
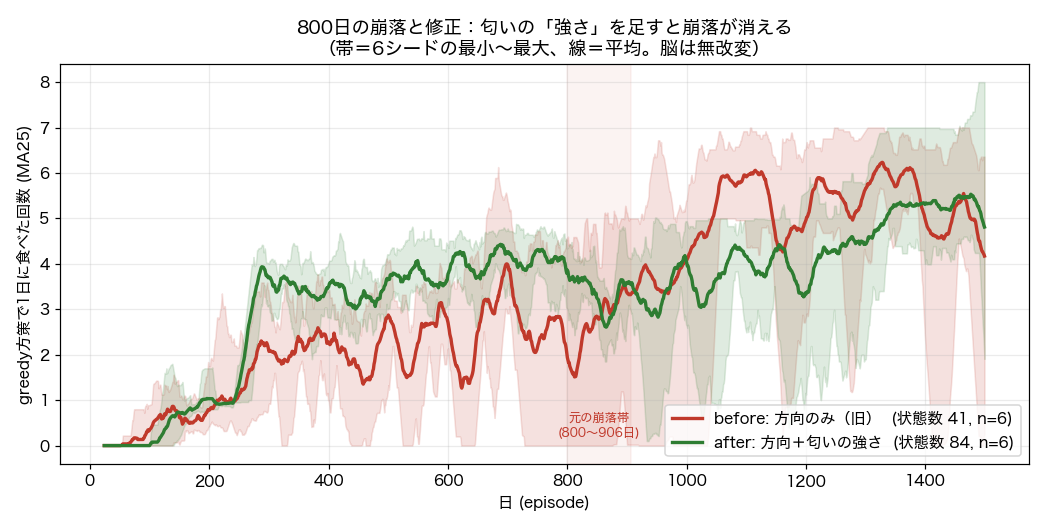
モデルを直す前に、入力を直す。区別すべきものが、同じ値になっていないか。新しい感覚を足すたびに、これを確かめる。
次の装置には、もう一匹を置く。
補足
- Universe 25: John B. Calhoun による閉鎖環境でのマウス実験。餌や水が十分にあるにもかかわらず、過密化のなかで繁殖や社会行動が崩れ、群れが続かなくなったことで知られる。